Extract Experience From Resume Using Python

Text Mining 101 Mining Information From A Resume Kdnuggets
Information Extraction From Cv Different People From Different Fields By Priya Sarkar Medium

Python Resume Samples Velvet Jobs

Python Developer Resume Samples Velvet Jobs

Nlp Based Resume Parser Using Bert In Python

Extract Data Skills From Resume Using Pyresparser Python A Simple Resume Parser Youtube
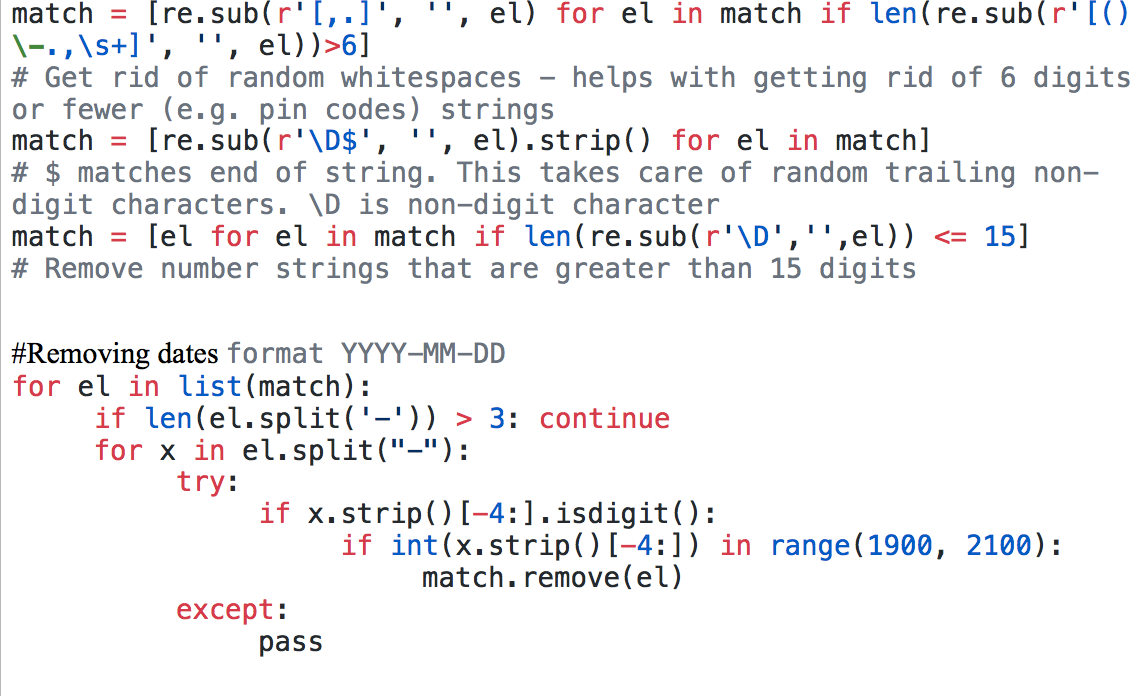
Pdfminer and doc2textpdf and doc.
Extract experience from resume using python. Im afraid resumes might be too dry for it to work nicely. For this we can use two Python modules. A resume is a brief summary of your skills and experience over one or two pages while a CV is more detailed and a longer representation of what the applicant is capable of doing.
So our main challenge is to read the resume and convert it to plain text. Im not sure Topic Modelling will help you here as it tries to extract abstract topics from text. An example of a resume may look like the below.
I am trying to process a lot resume in Python. A resume parser The reply to this post that gives you some text mining basics how to deal with text data what operations to perform on it etc as you said you had no prior. Is there a good way to do this besides using regex to extract certain fields from the resume assuming I.
A resumeCV generator parsing information from YAML file to generate a static website which you can deploy on the Github Pages. Resume-template resume cli yaml github-page hexo resume-creator cv-generator resume-parser resume-builder resume-app barn. Resume parser Premium resume parsing services have been moved to Resume-ParserPlease try the demo for free and give us your feedback A resume parser used for extracting information from resumes Built with and coffee.
A step by step guide to building your own Resume Parser using Python and natural language processing NLP. Saying so lets dive into building a parser tool using Python. I have extracted names by working with the Core NLP server I had extracted skills by giving in a set and comparing the words.
One of the cons of using PDF Miner is when you are dealing with resumes which is similar to the format of the Linkedin resume as shown below. Exactly like resume-version Hexo. This problem is called Named Entity Recognition Named-entity recognition NER also known as entity identification entity chunking and entity extraction is a subtask of information extraction that seeks to locate and classify named entities in text.

Python Software Engineer Resume Samples Velvet Jobs

3 Python Developer Resume Examples For 2021 Resume Worded Resume Worded

Build Your Own Resume Parser Using Python And Nlp Blog Prompt Api

Developer Python Resume Sample Ready To Use Example Shriresume

3 Python Developer Resume Examples For 2021 Resume Worded Resume Worded

Extracting Custom Entity From A Pdf Resume Using Python Spacy Entity Recognition Youtube

Programmer Resume Example Writing Tips Resume Genius

Resume Evaluation For Industrial Engineering Entry Level Position Resumes

Data Scientist Data Analytics Resume Samples Velvet Jobs

Research Data Analyst Resume Sample Mintresume

Transitioning To Software Engineer From Sci Fi Author Publisher Resume Help More Detail In Comments Resumes

How To Build The Perfect Data Engineer Resume With Examples Springboard Blog

Python Packages For Pdf Data Extraction By Rucha Sawarkar Analytics Vidhya Medium

